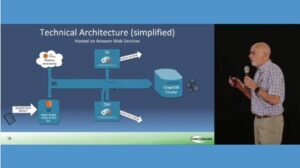
My recent presentations at SWIB23 (YouTube), and the Bibframe Workshop in Europe, attracted many questions; regarding the how, what, and most importantly the why, of the unique cloud-based Linked Data Management & Discovery System (LDMS) we developed, in partnership with metaphacts and Kewmann, in a two year project for the National Library Board of Singapore (NLB).
Several of the answers were technical in nature. However, somewhat surprisingly they were mostly grounded in what could best be described as business needs, such as:
- Seamless Knowledge Graph integration of records stored, and managed in separate systems
- No change required to the cataloging processes within those systems
- Near real time propagation of source data changes into the consolidated Knowledge Graph
- Consolidated view of all entity references presented for search, discovery, and display
- Individual management, update, or suppression of knowledge graph entities and attributes
Let me explore those a little…
✤ Seamless Knowledge Graph integration of records stored, and managed in separate systems – the source data for NLB’s Knowledge Graph comes from four different systems.
- Library System (ILS) – contains 1.5M+ bibliographic records – exported in MARC-XML format
- Authority System (TTE) – a bespoke system for managing thousands of Singapore and SE Asian name authority records for people, organisation, and places – exported in bespoke CSV format
- Content Management System (CMS) – host of content and data for several individual web portals, serving music, pictures, history, art, and information articles, etc. – exported in Dublin Core format
- National Archives (NAS) – data and content from documents, papers, photographs, maps, speeches, interviews, posters, etc. – exported in Dublin Core format
These immediately provided two significant challenges. Firstly, none of the exported formats are a linked data format. Secondly, the exported formats are different – even the two DC formats differ.
An extensible generic framework to support individual ETL pipeline processes was developed, one pipeline for each source system. Each extracts data from source data files, transforms them into a linked data form, and loads them into the knowledge graph. The pipeline for ILS data utilises open source tools from the Library of Congress (marc2bibframe2) and the Bibframe2Schema.org Community to achieve this in a ‘standard’ way. The other three pipelines use a combination of source specific scripting and transform logic.
When establishing the data model for the knowledge graph, a combination of two vocabularies were chosen. BIBFRAME, to capture detailed bibliographic requirements in a [library sector] standard way, and Schema.org to capture the attributes of all entities in a web-friendly form. Schema.org was chosen as a lingua franca vocabulary (all entities are described in Schema.org in addition to any other terms). This greatly simplified the discovery, management and processing of entities in the system.
✤ No change required to the cataloging processes within those systems – the introduction of a Linked Data system, has established a reconciled and consolidated view of resources across NLB’s systems, but it has not replaced those systems.
This approach has major benefits in enabling the introduction and explorative implementation of Linked Data techniques without being constrained by previous approaches, requiring a big-bang switchover, or directly impacting the day-to-day operations of currently established systems and the teams that manage them.
However, it did introduce implementation challenges for the LDMS. It could not be considered as the single source of truth for source data. The data model and management processes had to be designed to represent a consolidated source of truth for each entity, that may change due to daily cataloging activity in source systems.
✤ Near real time propagation of source data changes into the consolidated Knowledge Graph – unlike many Knowledge Graph systems which are self contained and managed, it is not just local edits that need to be made visible to users in a timely manner. The LDMS receives a large number, sometimes thousands in a day, of updates from source systems. For example, a cataloguer making a change or addition in the library system would expect to see it reflected within the LDMS within a day.
This turn around is achieved by the automatic operation of the ETL pipelines. On a daily basis they check a shared location on the NLB network, to where update files are exported from source systems. Received files are then processed through the appropriate pipeline and loaded into the knowledge graph. Activity logs and any issues arising are reported to the LDMS curator team.
✤ Consolidated view of all entity references presented for search, discovery, and display – in large distributed environments there are inevitably duplicate references to people, places, subjects, organisations, and creative work entities, etc. In practice, these duplications can be numerous.
For example, emanating from the transformation of library system data, there are some 160 individual person entity references for Lee, Kuan Yew (1st Prime Minister of Singapore). Another example, Singapore Art Museum, results in 21 CMS, 1 TTE, and 66 ILS entities. In each case, users would only expect to discover and view one consolidated version of each.
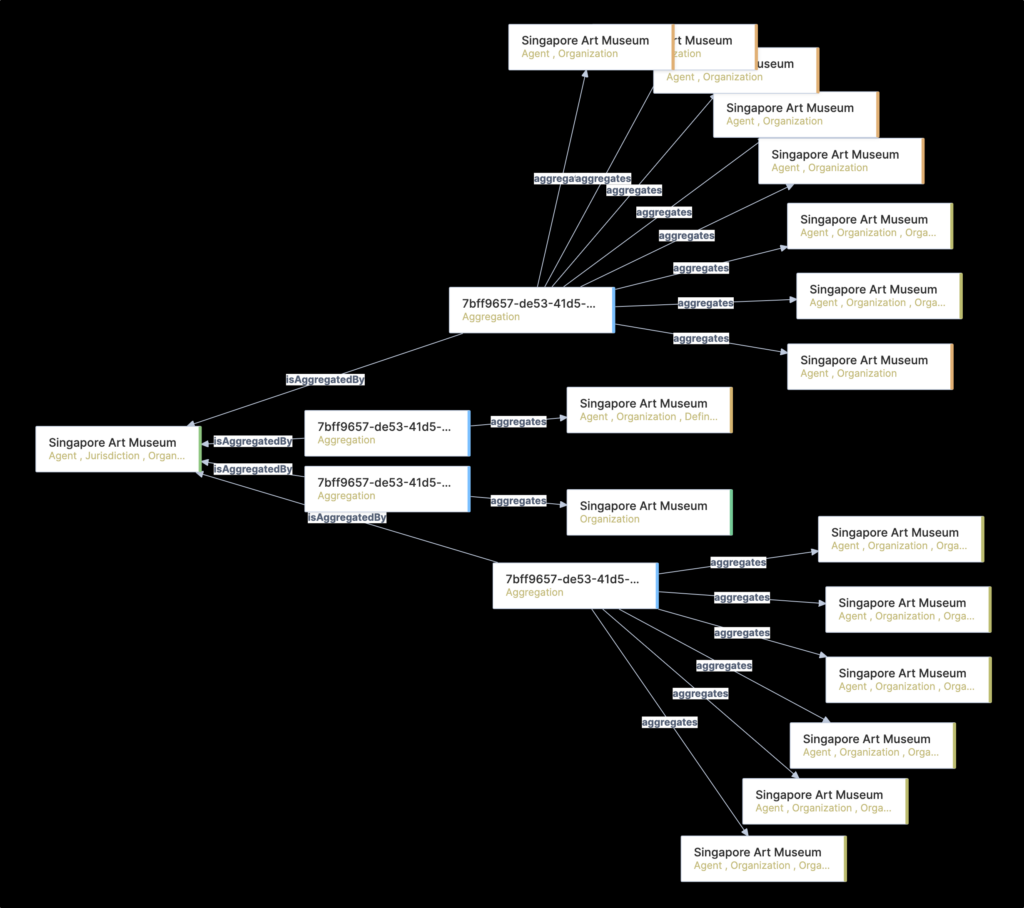
To facilitate the creation of a consolidated single view, whilst acknowledging constantly changing source data, a unique aggregation data model was developed. Aggregation entities track the relationship between source data entities, and then between sources, to resolve into primary entities used for discovery and display.
This approach has resulted in some 6 million primary entities, to be exposed to users, derived from approximately 70 million source entities.

Another way you could view this is as what I describe as an entity iceberg.
70 million Person, Place, Organization, Work, and Subject entities derived from regular updates from source systems, aggregated and reconciled together below the surface. A process that results in a consolidated viewable iceberg tip of 6 million primary entities.
Managed via a staff interface these primary entities drive knowledge graph search, discovery, and display for users.
✤ Individual management, update, or suppression of knowledge graph entities and attributes – no matter how good automatic processing is, it will never be perfect. Equally, as cataloguers and data curators are aware, issues and anomalies lurk in source data, to become obvious when merged with other data. Be it the addition of new descriptive information, or the suppression of a birth date on behalf of a concerned author, some manual curation will be needed. However, simply editing source entities was not an option, as any changes could well then be reversed by the next ETL operation.

The data management interface of the LDMS provides the capability to manually add new attributes to primary entities and suppress others as required. As the changes are applied at a primary entity level, they are independent from and therefore override constantly updating source data.
The two year project, working in close cooperation with NLB’s Data Team, has been a great one to be part of – developing unique yet generic solutions to specific data integration and knowledge graph challenges.
The project continues, building on the capabilities derived from this constantly updated consolidated view of the resources curated by NLB. Work is already underway in the areas of user interface integration with other systems, and enrichment of knowledge graph data from external sources such as the Library of Congress – Watch this space.